Is Your Drug Discovery Data AI-Ready? Unifying and Contextualizing Drug Discovery Data

While artificial intelligence (AI) and machine learning (ML) have been used in drug discovery since at least the 1990s, the first mention of AI dates back to 1950 in a paper written by Alan Turing. Although AI isn’t entirely new in the world of drug discovery, the recent advent of generative AI has heightened excitement about the power of these tech tools to the next level.
The use case for AI in drug discovery is strong. Advanced pharmaceutical research is creating ever more data that is challenging to analyze effectively without powerful software tools. At the same time, scientists are under pressure to accelerate the pace of innovation.
When embarking on the use of AI in drug discovery, however, many organizations confront a significant challenge. They find that their datasets are isolated and poorly managed. Data has often been collected without useful context or metadata that describes what the data entails, leaving it unprepared for effective use by AI or ML algorithms.
Organizations can address this challenge by adopting a data management strategy and deploying a unified R&D software platform that prepares data properly for AI.
An Effective AI-Ready Data Strategy Requires Metadata
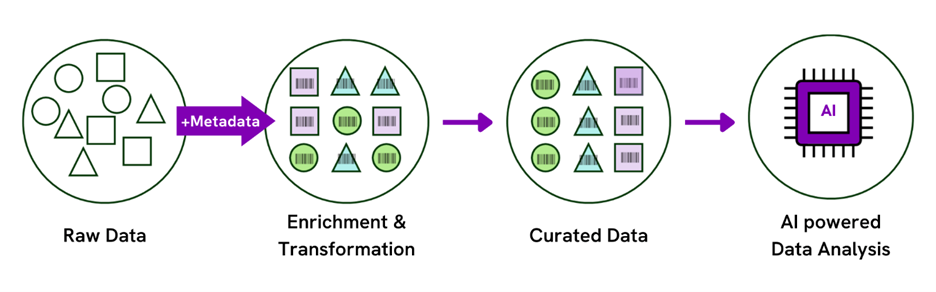
When using any analysis software, and more so with ML and AI, data needs context. That means metadata—data about data. In drug discovery, metadata includes information about the methods used to collect the data, the conditions under which experiments were conducted, the parameters measured, and the protocols followed.
Tagging and metadata make data effective for training ML models, which continue to improve over time. For example, having more information on drug candidates’ toxicity can better inform ML models. Without that additional information, the drug candidate data is susceptible to misinterpretation by AI algorithms, potentially steering researchers down the wrong path.
For these reasons, ensuring the accuracy and completeness of the metadata is crucial. Metadata capture (also referred to as data enrichment) works best when it is intuitively integrated into the experimental process, when it is top of mind for the researcher. Properly enriched data enables AI algorithms to perform the analytics that can reveal meaningful patterns.
Structure Without Flexibility Leads to Poor Results
Although well-organized data and metadata are essential for AI and ML, flexibility is also critical. Scientific discovery is inherently unpredictable, and data captured today may need to answer questions that arise tomorrow.
Many scientific organizations use rigid data schemas with strict parameters. A rigid data model forces scientists to fit complex data into limited input boxes, often at the expense of nuance and detail that could be crucial for future discoveries.
Data bound too early into a rigid schema may lose its potential to be re-interrogated under a new scientific lens. Additionally, rigid data models can impede the integration of disparate data types, which is an increasingly critical capability as research becomes more interdisciplinary.
In the context of AI, where the richness of the training dataset directly influences the performance of the models, the limitations imposed by rigid data schemas can be particularly problematic. ML models trained on incomplete or inadequately structured datasets may yield suboptimal or biased predictions, undermining the utility of the insights they generate.
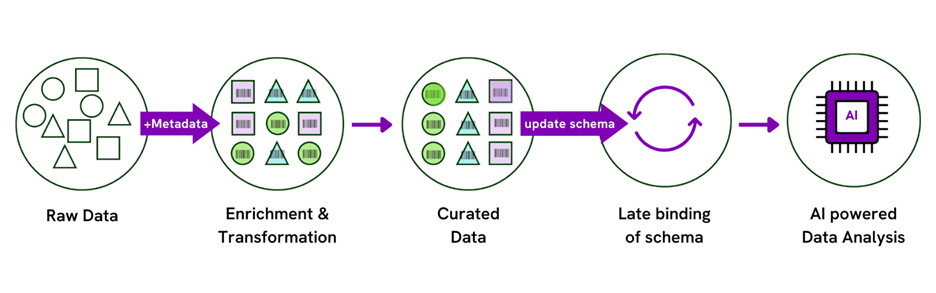
Late Binding of Schema Enables Adaptation
A methodology called “late binding of schema” involves capturing data in a way that leaves room for changing the data’s presentation and restructuring it when needed. This is a more future-proof approach that acknowledges the unpredictable nature of scientific discovery and the diverse needs of data analytics, including AI. With late binding of schema, the data structure can be defined and modified closer to the time of analysis, allowing for new models as new hypotheses arise.
This methodology preserves the full informational content of the data—the metadata—while also providing the flexibility to adapt to new research questions and perspectives. It facilitates the integration of varied data types and enables data to be repurposed for unforeseen analytical needs. It enables the data of today to be harnessed for the questions of tomorrow.
How a Unified R&D Data Platform Sets the Stage for AI Success
Drug discovery organizations can prepare for AI by deploying a unified R&D platform, like Signals One™ by Revvity Signals, a unified solution for the capture, processing, modeling, and analysis of scientific data.
With Signals One, customizable and requirable fields ensure that scientists properly annotate data as experiments are conducted—when it’s top of mind. Intricate experimental details are recorded with precision and clarity as part of the scientist’s workflow, ensuring that every data point can be fully leveraged by AI algorithms. The use of the late binding of schema methodology provides the flexibility needed for data to be restructured and re-interrogated as new hypotheses arise. The platform also makes it easy to segment data, so that ML algorithms can be trained on appropriate subsets—avoiding the dilution caused by irrelevant information—to increase the quality of analytical results.
By using Signals One, organizations ensure that their drug discovery data is AI-ready. Signals One provides users with three distinct advantages:
- An Integrated Data Ecosystem: Signals One offers a more comprehensive, end-to-end solution that handles data from multiple sources in a single platform. This integration allows for more seamless data preparation for AI applications. Further, Signals One’s all-in-one environment makes it easy to capture descriptive data at every stage of the experimental process, to support the Design-Make-Test-Decide R&D lifecycle.
- Advanced Analytics: With its years of experience preparing data for use in the natively integrated Spotfire®, Revvity Signals has a strong background in advanced analytics, which translates into better data preparation and feature engineering capabilities for AI models.
- Industry-Specific Expertise: With its roots in life sciences, Signals One has deep domain knowledge that allows for more nuanced data handling and preparation, especially for complex scientific data.
Summary: Preparing Drug Discovery Data for AI Success
The transformative power of AI inspires optimism for the future of drug discovery, but AI is only as powerful as the data it consumes. AI needs data that has the proper quality, detail, and context.
By deploying a unified R&D SaaS solution like Signals One, drug discovery organizations can ensure that their data is unified and well contextualized. They can bring together diverse datasets and capture experimental metadata accurately, while maintaining the flexibility to modify the data structure to address future analytical needs.
With the power of Revvity Signals, drug discovery teams can transform vast volumes of information into a structured, navigable resources ready for complex analysis by today’s AI tools and those of tomorrow.

Chris Stumpf
Director of Drug Discovery Informatics Solutions Revvity Signals Software, Inc.Chris Stumpf is Director of Drug Discovery Informatics Solutions at Revvity Signals. He has over 25 years of experience in the analytical instrumentation and informatics industry, spanning pharmaceuticals and life sciences to chemicals and materials. Chris holds a Ph.D. in Analytical Chemistry and Mass Spectrometry from Purdue University.