Solving Data Bottlenecks by Automating and Scaling Wet-Lab Data Analysis

Discover how automated and scalable wet lab data analysis can solve data bottlenecks in research. Read our blog for insights from Revvity Signals.
As the sheer volume of assay and high-throughput screening (HTS) data continues to grow, automated data analysis pipelines have become critical for scientists working in wet labs.
In fact, it should come as no surprise that the top request of pharma lab scientists is data automation pipelines.
[By the way, we agree completely! That’s why data automation pipelines are available in Signals One Data Processing – more below.]
Where is all of this data coming from?
According to Statista, between 2022 and 2025 the volume of data – the total quantity of global data created, captured, copied, and consumed globally – is expected to nearly double, reaching 181 zettabytes. Scientific research is a major contributor to this growth. Automation of front-end data collection, combined with more robust instrument integrations and other advances in both science and technology, have been key accelerators of our data generation rate.
Have we shifted the scientific data bottleneck?
The absence of back-end automation of analysis, however, has emerged as a new roadblock, moving the data logjam further downstream from data collection. In nearly every discussion of the Lab of the Future, data automation plays a key role. From Technology Networks (Towards the Lab of the Future), Joanna Owens writes:
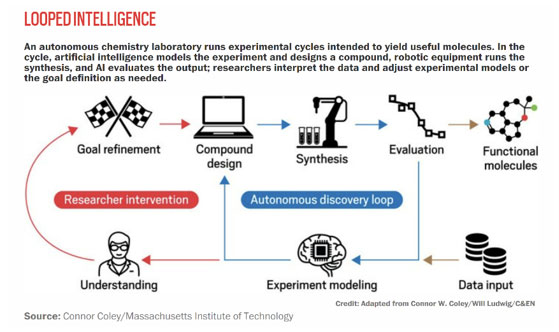
“In the lab of the future, researchers will be freed from manual, repetitive experimental tasks, as automated tools and artificial intelligence-powered robots carry out protocols, collect and analyze data, and design subsequent experiments, freeing up time for humans to focus on interpreting what the results mean and addressing the bigger scientific questions.”
But according to Rick Mullen, Senior Editor at Chemical & Engineering News (The Lab of the Future is Now), we’ve likely already crossed the threshold into the Lab of the Future as AI-directed automation signals a new era of research.
Automating Data Analysis Pipelines for Wet-Labs
Question: If the new data bottleneck is analysis, how do you solve it?
Answer: Automation.
Leveraging automated data analysis pipelines avoids the need for anyone to interactively go through a workflow.
This saves time, ensures consistent and repeatable analysis, and lowers the chance of introducing human errors encountered during workflows – hence making the data analysis pipeline automation we mentioned earlier a top ‘must have.’ The need for this is so acute, in fact, that academic labs are trying to create their own versions as open-source software.
Breaking the Data Analysis Bottleneck
A key challenge facing scientists is time – namely, the lack of it – to work through data analysis workflows. This is where automated data processing comes into play. Workflows developed in Revvity Signals One Data Processing are easily translated into Analysis Pipelines, which are then run in Spark cluster inside Signals One Data Factory – without user interaction. Presto!
Data processing is easily scaled-up, saving time and ensuring data accuracy and availability.
Solutions from assay development through large molecule development
At Revvity Signals, we’ve built scientific intelligence into all our Signals solutions to help wet lab workflows.
Signals OneTM is comprised of Signals Notebook, Signals One Data Processing and Signals One Data-driven Analytics – all of which are seamlessly integrated with one another.
It’s the Signals One Data Processing solution, in particular, which allows users to design data processing workflows in a low-code/no-code platform. And while automation is essential to truly realize data efficiencies, Signals One Data Processing workflows can also be run traditionally in an interactive (manual self-service) way.
Signals One Data Processing:
- Reads plate data and enables the addition of well-specific metadata.
- Executes data normalization and first data quality control steps to enable cross-campaign standardization of results.
- Feeds data into automated individual outlier detection (e.g., using GESD and curve fitting) with an out-of-the-box engine containing all industry-standard multi-parameter curve fit models. The engine is further extendable by the scientist.
- Stores and indexes the resulting curve fits in Signals Data Factory for subsequent SAR (Structure Activity Relationship) analysis.
The data processing workflow design is made possible through Revvity Signals own application data framework on top of Spotfire™. It captures all steps and calculations of the workflows as JSON definitions.
Signals One Data Processing brings assay development, low throughput to ultra-high throughput production assays, High Content Screening, and in vivo studies together – and then automates your data analysis workflows freeing scientists up to do more science.
Want to get started with your automated, hands-free, no-bottleneck Lab of the Future? Explore our Interactive Demo Gallery or contact us today.
Or learn more in our whitepaper: How to Optimize In Vitro and In Vivo Data Analysis in Drug Discovery.