How Spotfire Helped a Biotech Startup Manage Rapid Data Growth and Analysis


Introduction
MOMA Therapeutics, a clinical-stage precision medicine company targeting highly dynamic proteins via a small molecule approach, seeks to identify drug discovery targets based on the family of enzymes known as molecular machines. Early in the company's development, they recognized the need for a robust data management platform to support their complex research.
Having already identified 400 proteins in the molecular machines family, MOMA was poised to advance into target discovery. This next phase, involving extensive genome experimentation, would significantly increase their data management requirements. They needed to make complex analyses accessible to non-computational scientists, seamlessly integrate chemical and biological data analysis, and provide a feedback loop for informed decision-making. They needed a solution that could support collaborative research among remote teams, be deployed quickly, and adapt to their continued growth. A solution that would provide access to data visualizations that answer questions for scientists in the research laboratory as well as bioinformaticians at the desk, without adding time and effort to their workloads.
Spotfire, the advanced analytics and visualization scientific software, available from Revvity Signals, met all these requirements. MOMA implemented Spotfire using Amazon Web Services enabling their diverse scientific teams to share complex analyses, collaboratively explore research questions while maintaining data integrity, and accelerate discovery through self-service data visualization.
A Cloud-First Strategy Suits a Biotech Startup
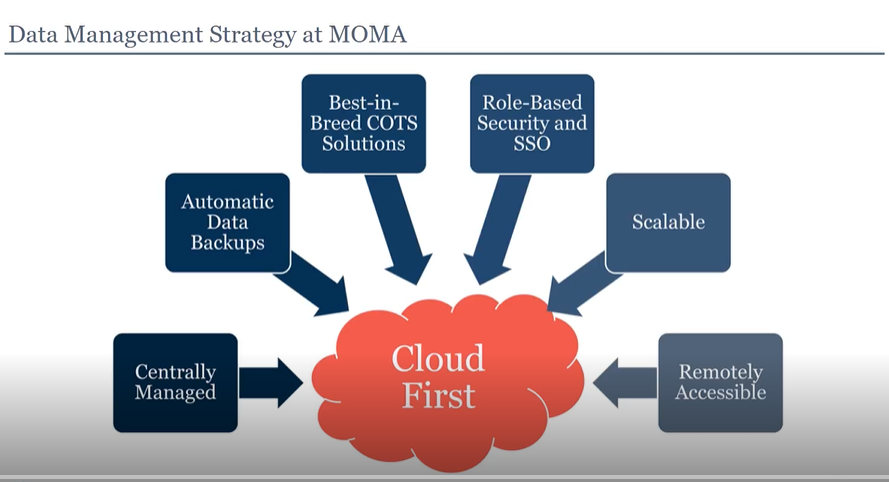
The timing of MOMA's launch in early 2020, coinciding with the Covid-19 pandemic shutdown, necessitated a cloud-first technology strategy with remote access capabilities. They began with an Amazon Web Services (AWS) cloud infrastructure called Biotech Blueprint, which they set up in just 20 minutes for $45 monthly.
The next step was to implement a data management application. MOMA's discovery scientists specifically requested Spotfire, which was already an established partner vendor in Biotech Blueprint. This existing partnership allowed MOMA to rapidly deploy the visualization platform within their virtual private cloud. After a five-week evaluation confirmed Spotfire was the right solution, the transition to full adoption proceeded seamlessly. The team launched a new production environment with immediate availability to all employees, even preserving visualizations created during the testing phase.
This setup required minimal effort from the MOMA technology team. The lightweight AWS infrastructure needs little management, onboarding new Spotfire users is straightforward, and staff can access it from anywhere. The solution is also readily scalable—a critical feature for a growing company.
Cycles of Iterative and Overlapping Analysis: Everything, Everywhere, All at Once
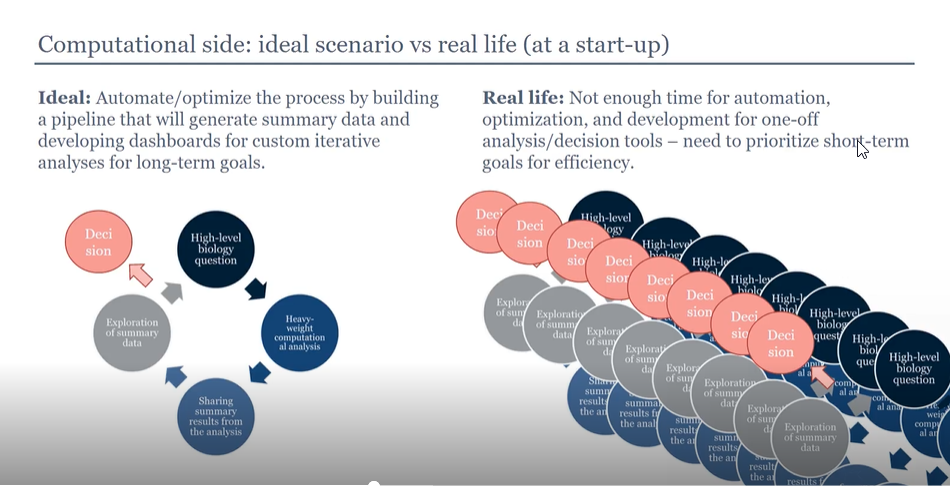
MOMA's data management requirements were driven by their research approach. A particular challenge was sharing complex datasets developed by computational biologists with other researchers in an iterative, multistep analytical cycle.
A typical MOMA drug discovery project begins with a high-level biology question. Computational biologists perform comprehensive analyses and share results. Experimental scientists then probe the information to determine next steps. This process often prompts revisiting the initial biology question, leading to new computational analyses.
This iterative analytical practice—identifying questions, performing analyses, sharing datasets, exploring results, and making decisions—repeats continuously. Some analyses prove short-lived as teams refine their questions and approaches. Adding complexity, multiple explorations of different datasets and questions occur simultaneously—it's everything, everywhere, all at once.
The Data-Sharing Problem
Throughout this iterative cycle, computational biologists must share complex dataset summaries with experimental researchers. The data must remain accessible, secure, and protected from errors that could arise during handling by multiple scientists.
Further complicating matters, computational biologists' modeling outputs aren't user-friendly for non-specialists. Making these complex analyses accessible requires translating them into various graphical representations—scatter plots, volcano plots, box plots, and group plots—potentially for hundreds of factors under consideration.
Creating custom visualizations for every analysis would be extremely time-consuming for the computational biology team. They would also need to update dashboards with revised data and maintain working links. Worse, they would invest significant time in analyses that might be quickly discarded during the research process.
The Data-Sharing Solution: Self-Service Data Exploration
Spotfire's intuitive visualization tools solved MOMA's data-sharing challenges. Individual researchers could independently explore complex datasets in customized graphical formats, with one-click access to underlying data tables when needed.
This interactive self-service model enabled MOMA to separate the analysis from the analyst: Experimental teams could explore datasets while computational biologists moved on to new projects.
These capabilities streamlined everyone's workflow. Computational biologists no longer needed to develop custom tools for each research question—particularly valuable given that some analyses would be short-lived. Meanwhile, experimental scientists gained immediate access to both data and visualization tools.
Integration of Chemical and Biological Data
Spotfire further enhanced the MOMA team's efficiency by supporting data and analyses spanning biology and chemistry. Computational biologists didn't need to determine which structures chemists preferred. Scientists from different domains could visualize biological and chemical data according to their specific needs.
This cross-domain capability facilitated research into the interplay between chemistry and biology in drug-target interactions. Researchers could readily expand traditional structure-activity relationship (SAR) experiments to incorporate gene sequences through sequence-structure-activity relationship (SSAR) studies.
Maintaining Data Integrity and Data Persistence
Spotfire allowed scientists to explore research questions while protecting the integrity of the original data set. Data persistence was ensured through permanent URLs, which could be shared in presentations and discussions, and easily retrieved later with term searches—whether by current or new team members.
Summary: Accelerated Discovery Through Strategic Data Management
MOMA Therapeutics successfully addressed its expanding data challenges by implementing Spotfire in an AWS cloud environment. This solution delivered critical capabilities: self-service data exploration for non-computational scientists, seamless integration of chemical and biological analyses, secure data integrity, and persistent accessibility. The cloud-based approach enabled remote collaboration while providing the scalability needed for a growing biotech. By empowering experimental scientists with Spotfire’s interactive visualization capabilities and freeing computational biologists from creating custom visualizations, MOMA established an efficient workflow that accelerates its molecular machine–focused drug discovery process.
To learn more about Spotfire at Revvity Signals, visit here.

End-to-end workflow support across scientific disciplines.

The Standard for Chemical Drawing.

End-to-end Clinical Data Science Platform.